Modellieren sie noch oder generieren sie schon?
Law2Logic – Facharchitekturen mit KI erstellen
Ist es möglich, mit generativen Sprachmodellen aus unstrukturierten Dokumenten eine Facharchitektur zu erzeugen? Am Beispiel einer fiktiven Krankenkasse untersuchen wir, welche Chancen und Herausforderungen bei der automatischen Erstellung auf Basis textueller Dokumentationen bestehen.
Facharchitekturen sind zentraler Baustein für die Steuerung von Behörden, Sozialversicherungsträgern und Unternehmen. Sie werden eingesetzt, um strategische, operative und IT-Entscheidungen auf einer fundierten Informationsbasis zu treffen. Eine gute Facharchitektur liefert das Fundament, um Zusammenhänge und Abhängigkeiten in modernen Organisationen zu erkennen und effektiv zu bewältigen. Herausforderung ist aber, dass der initiale Aufbau und die langfristige Pflege einen erheblichen Aufwand erzeugt. Können die Fortschritte in generativer Künstlicher Intelligenz (KI) und Large Language Models (LLM) helfen?
Oder um es mit der Werbung eines schwedischen Möbelhauses zu sagen:
Modellieren (d.h. malen) Sie noch oder generieren Sie schon?
Heute werden Facharchitekturen meist manuell erzeugt. Aufbau und Pflege sind mit viel Aufwand verbunden. Aufwand, der besser in die Verbesserung der Organisation fließen sollte, anstatt in die (leider) notwendige Erfassung von Inhalten für das Architekturmodell. An dieser Stelle liegt ein beachtlicher Hebel, um Potentiale freizulegen. Konkret ergeben sich dabei folgende Fragen:
- Ist es möglich, mit der automatischen Generierung eines Architektur-Modells auf Basis unstrukturierter Textdaten eine signifikante Reduzierung des Aufwandes der Modellerstellung zu erreichen?
- Gelingt es, das Architekturmodell durch die Nutzung individueller Inhalte besser an der eigenen Organisation auszurichten, anstatt nur „KI generierte Allgemeinplätze“ zu erhalten?
- Können strategische, organisatorische und technische Entscheidungen mit Hilfe eines generierten Modells vereinfacht und beschleunigt werden?
- Stehen wir vor einem grundlegenden Wandel in der Art und Weise, wie Facharchitekturen erstellt und „betrieben“ werden?
- Ist die Zeit der klassischen Modellierungssoftware vorbei?
Sehen wir uns den aktuellen Stand einmal an.
In Behörden, Sozialversicherungsträgern und Unternehmen sind unstrukturierte Daten die Regel. Etwa 90 % aller Informationen sind dort unstrukturiert und stellen traditionelle Methoden der automatischen Verarbeitung vor Herausforderungen. Das führt zu Ineffizienzen und dem Risiko von Informationsverlusten [1]. Die Integration von künstlicher Intelligenz, maschinellem Lernen und grafenbasierter Dokumentation ermöglicht die Extraktion und Verarbeitung von Inhalten unterschiedlicher Quellen wie Arbeitsanweisungen, Verfahrensbeschreibungen, Rechtsdokumenten, Krankenakten und Jahresabschlüssen. Das ebnet den Weg zu einer automatisierten und datengetriebenen Architekturdokumentation [1][2].
Durch automatische Extraktion lassen sich Modelle entwickeln, die real existierende Entitäten und deren Beziehungen widerspiegeln [3][4] und sich an Veränderungen der Organisation anpassen. Die dynamische Anpassung ist entscheidend, denn besonders die kontinuierliche Pflege von (Fach-)Architekturen erzeugt viel Aufwand. Die Realität verändert sich in einer Geschwindigkeit, die es nahezu unmöglich macht, ein großes Modell manuell aktuell zu halten. Der Einsatz von LLMs zur Extraktion architekturrelevanter Inhalte aus Dokumenten ist demnach naheliegend.
LLM-Kombination im hybriden Ansatz
Bedenken hinsichtlich des Datenschutzes lassen viele Anwender davor zurückschrecken, die eigenen ggf. vertraulichen Daten an Cloud-basierte Dienste zu senden. Entwicklungen im Bereich der KI haben in den vergangenen 12 Monaten dazu beigetragen, dass das Potenzial generativer Architekturmodellierung auch lokal ausgeschöpft werden kann. Speziell ein hybrider Ansatz eröffnet den Weg, die Fähigkeiten sehr großer Sprachmodelle „aus der Cloud“ (>100 Milliarden Modell-Parameter) mit dem datenschutzfreundlichen Einsatz „kleinerer“ LLMs im lokalen Netzwerk zu verbinden (s. Abbildung 1).
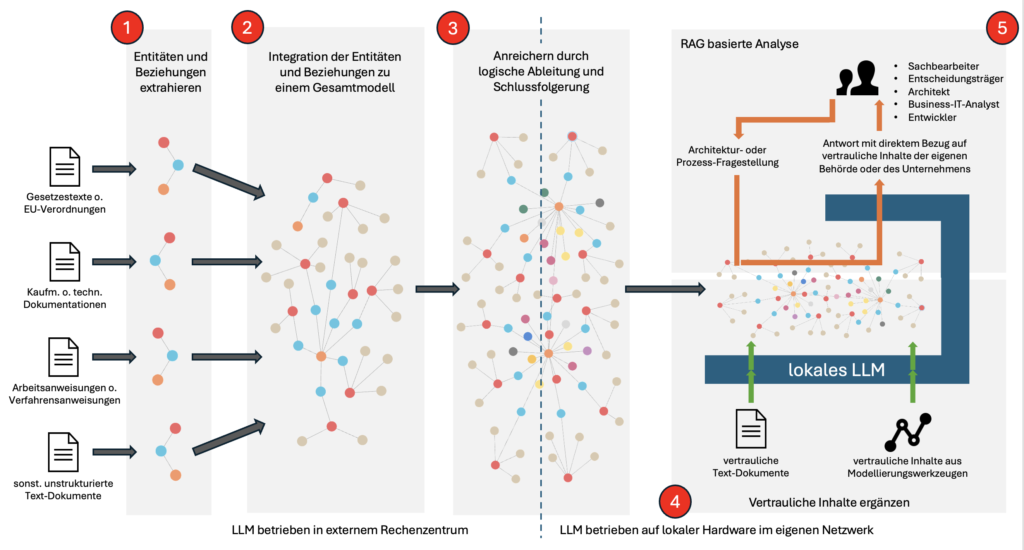
1. Ermittlung der Entitäten und Beziehungen
Der erste Schritt zur Generierung einer Facharchitektur nach dem hybriden Ansatz besteht in der Analyse der unstrukturierten Basistexte, die aus Datenschutzgesichtspunkten unkritisch sind, aber bereits einen guten Überblick über die Domäne der Behörde, Sozialversicherung oder des Unternehmens liefern. Hierfür wird ein großes Sprachmodell in der Cloud genutzt. Das LLM durchsucht die Texte nach Entitäten und Beziehungen, die für die Domäne relevant sind. Entitäten sind u.a. Personen, Organisationen, Orte oder Konzepte. Beziehungen beschreiben die Interaktionen bzw. Verbindungen zwischen den Entitäten. So entsteht eine Basis-Ontologie der betrachteten fachlichen Domäne.
2. Integration in einem Gesamtmodell
Im zweiten Schritt werden die extrahierten Entitäten und Beziehungen in einem Graphenmodell zusammengeführt. Ein Graph ist eine Datenstruktur, die aus Knoten (Entitäten) und Kanten (Beziehungen) besteht. Das ermöglicht die logische Darstellung verknüpfter Informationen, die aus unstrukturierten Texten extrahiert wurden. Das Modell dient als Fundament für die weitere Verarbeitung, Anreicherung und Analyse. Auch dieser Schritt wird mit Hilfe des großen LLM in der Cloud durchgeführt, um eine hohe Genauigkeit zu gewährleisten.
3. Automatische Anreicherung durch logische Schlussfolgerung
Im dritten Schritt wird das Graphenmodell durch logische Ableitung und Schlussfolgerung angereichert. Es werden Informationen automatisch aus den vorhandenen Daten abgeleitet, die implizit im Ursprungstext enthalten sind, aber erst durch logische Schlussfolgerungen von einem Sprachmodell erkannt werden. Die Anreicherung erweitert die Datenbasis, um umfassende Auswertungen und Analysen zu ermöglichen.
4. Ergänzung um vertrauliche Inhalte
Im vierten Schritt wird das Modell um vertrauliche Inhalte ergänzt. Durch lokale Verarbeitung wird sichergestellt, dass die Inhalte geschützt bleiben. Das umfasst sowohl Inhalte aus unstrukturierten Texten, wie auch strukturierte Inhalte aus (Architektur-)Modellierungswerkzeugen (z.B. Adonis, ARIS, BIC, Enterprise Architect, LeanIX, Signavio etc.). Die Ableitung erfolgt ausschließlich mit einem im eigenen Netzwerk betriebenen „kleinen“ LLM.
Dadurch wird die individuelle Situation einer Organisation berücksichtigt, ohne vertrauliche Daten zu kompromittieren. Im Unterschied zu Lösungen, die „nur“ allgemeine Antworten liefern, ermöglichen vertrauliche behörden-, sozialversicherungs- bzw. unternehmensspezifische Inhalte deutlich präzisere Architektur-Analysen. Vereinfacht gesagt, wird auf die Anfrage „Erstelle einen Order to Cash Prozess“ keine allgemeine Antwort auf Basis von ChatGPT oder anderen LLMs geliefert, sondern es wird der eigene spezifische Inhalt zugrunde gelegt und ein individuell passender Prozess generiert. Erst dann entsteht ein Modell, das wirklich die eigene Organisation beschreibt.
5. RAG-basierte Analyse
Der fünfte und letzte Schritt besteht im praktischen Einsatz des erstellten Facharchitekturmodells. Hierfür wird eine Abwandlung der Retrieval-Augmented Generation (RAG) Methode eingesetzt. RAG kombiniert die Stärken von Information-Retrieval und Textgenerierung, um präzise relevante Antworten auf Nutzerfragen zu erzeugen. Durch den Einsatz eines lokalen „Retrieval-LLM“ kann das erstellte Modell auf Basis der eigenen Inhalte datenschutzfreundlich abgefragt werden.
Beispiel: Law2Logic – Facharchitektur aus dem SGB V generieren
Von der Politik wird die Einführung digitaler Lösungen in Behörden, Verwaltungen und Sozialversicherungen gefordert. Gesetze bilden den fachlichen Ausgangspunkt für die Modernisierung der zugehörigen Prozesse. Deshalb bieten sich Rechtstexte an, um die praktische Umsetzbarkeit der Generierung einer Facharchitektur aus unstrukturierten Texten nach dem hybriden Ansatz in der Praxis zu untersuchen. Neben der politischen Bedeutung sind sie gekennzeichnet durch dichte Sprache und vielschichtige Interpretationsmöglichkeiten. Rechtstexte sind zudem eine Herausforderung für die automatisierte Analyse und erfordern fortschrittliche Methoden, um maschinenlesbare Strukturen zu extrahieren [6][7][8].
Als Beispiel betrachten wir das Sozialgesetzbuch V (SGB V) und erstellen daraus ein Facharchitekturmodell. Das SGB V beschreibt den juristischen Rahmen, in dem gesetzliche Krankenkassen, Aufsichtsbehörden, Krankenhäuser, Ärzte, Apotheken, Pflegeeinrichtungen, Versorgungszentren und weitere medizinische Dienstleister in Deutschland tätig sind. Es enthält für unser Beispiel u.a. den fachlichen Rahmen zur Ableitung einer Facharchitektur im Bereich einer fiktiven Krankenkasse.
Selbstverständlich sind für ein individuelles Architekturmodell in vielen Fällen zusätzliche (oftmals vertrauliche) Inhalte zu ergänzen. Um diesen Fall zu simulieren, betrachten wir zusätzlich Teile des Dokuments „Grundsätze für das Meldeverfahren mit den Elterngeldstellen nach § 203 Abs. 3 SGB V“ des GKV-Spitzenverbands und ergänzen daraus extrahierte Ergebnisse im Modell [9].
Hinweis: Aufgrund des Umfangs der Daten werden in diesem Artikel nur beispielhaft Ergebnisse vorgestellt. Der gesamte Knowledge Graph der 694 SGB V Paragrafen steht in einem Web-Portal online für weitere Auswertungen zur Verfügung. Bei Interesse an einem Online-Zugang zu diesem Datensatz senden Sie bitte eine kurze E-Mail von Ihrem Behörden-, Sozialversicherungs- bzw. Unternehmensaccount an info@magaseen.de oder nutzen das Kontaktformular unter Kontakt.
Ermittlung der Entitäten und Beziehungen des SGB V
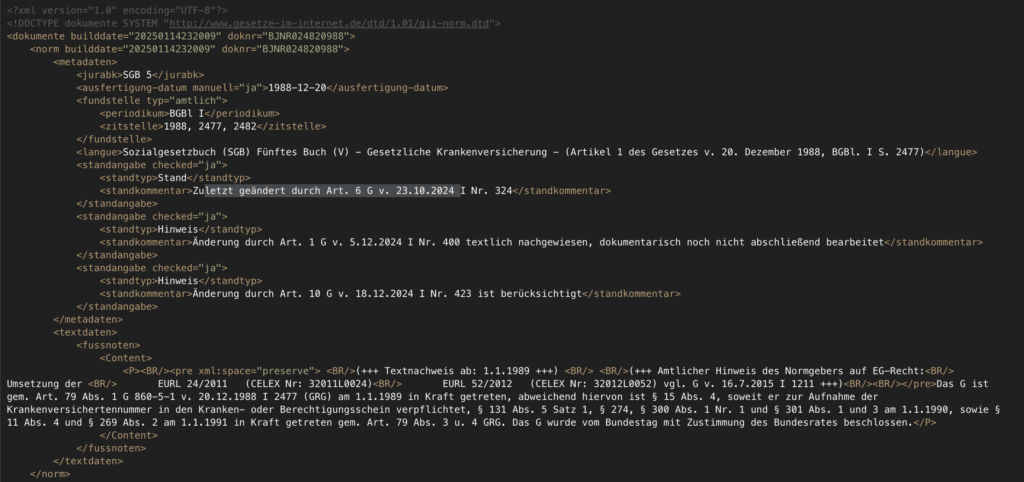
Die Inhalte des SGB V werden über die vom Bundesministerium der Justiz herausgegebene Webseite „Gesetze im Internet“ bezogen. Neben der Textversion stehen dort auch maschinenlesbare Formate zur Verfügung, von denen für die Extraktion der Entitäten und Beziehungen die XML-Version verwendet wird (Abbildung 2 zeigt einen Ausschnitt).
Die Generierung der Basisdaten erfolgt mit dem europäischen Sprachmodell „Mistral Large“, mit aktuell 123 Milliarden Parametern, welches an die besonderen Anforderungen der Gesetzesanalyse angepasst wurde. Ausgeführt wird das Modell im Rechenzentrum vom Mistral AI. Das gewährleistet, dass europäische Datenschutzgesetze eingehalten und kein Datenabfluss an amerikanische oder chinesische Anbieter erfolgt (auch wenn die im Beispiel verwendeten Inhalte frei verfügbar und damit in dieser Hinsicht unkritisch sind).
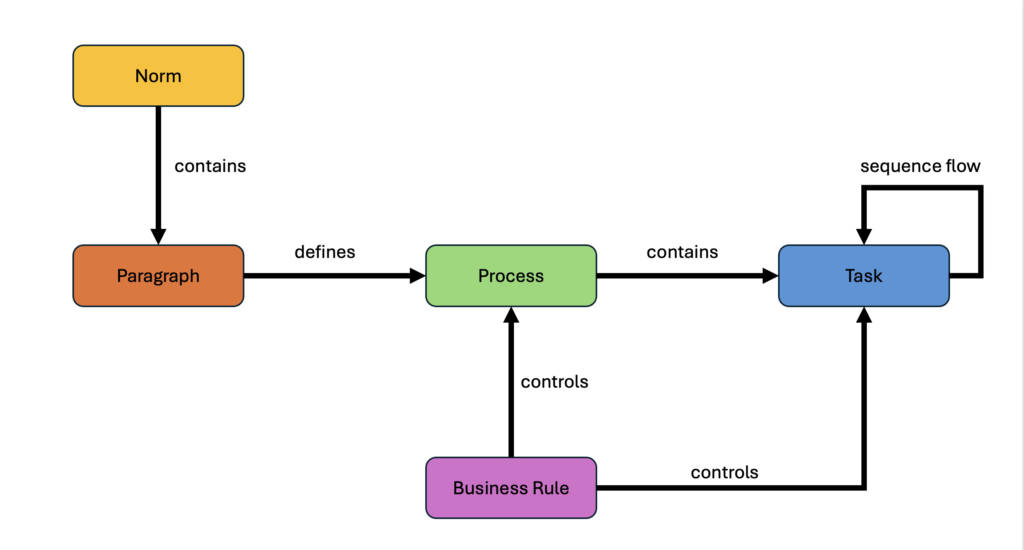
Das LLM extrahiert zu jedem Paragrafen die implizit enthaltenen Prozesse, die Arbeitsschritte je Prozess, den Sequenzfluss der Arbeitsschritte und die logischen Geschäftsregeln in der Business Rule Markup Language (BRML). Die BRML ist ein in XML beschriebenes neutrales Austauschformat für Geschäftsregeln.
Es entsteht ein initialer Knowledge Graph mit folgendem Mengengerüst:
- 1 Gesetz (Norm)
- 694 Paragrafen (Paragraph)
- 5100 Unterprozesse (Process),
- 16988 Arbeitsschritte (Task) und
- 5100 Geschäftsregeln (Business Rule)
Abbildung 3 zeigt die Zusammenhänge der Entitäten in einem vereinfachten Meta-Modell.
Alle nachfolgend aufgeführten Ergebnisse sind vollständig mit Hilfe des LLM und durch Algorithmen aus der XML-Datei des SGB V generiert. Es wurden keine Inhalte manuell ergänzt oder verändert. Das schließt auch kleinere Abweichungen und Fehlinterpretationen des LLMs ein, so dass die aufgeführten Ergebnisse eine Bewertung der Qualität der Generierung ermöglichen.
Nachfolgend werden beispielhaft die Ergebnisse zu folgenden Paragrafen genauer vorgestellt:
- § 24i – Mutterschaftsgeld -> als Beispiel für die Ableitung operativer Facharchitekturinhalte
- § 203 – Meldepflichten bei Leistung von Mutterschaftsgeld, Elterngeld oder Erziehungsgeld -> als Beispiel für die Ableitung implementierungsbezogener (technischer) Facharchitekturinhalte
Abbildung 4 zeigt die verwendeten Ausgangstexte des § 24i und § 203. Nur diese Texte wurden für die Generierung der Ergebnisse der beiden Paragrafen verwendet.
Paragraf 24i regelt die Zahlung von Mutterschaftsgeld an weibliche Mitglieder während der Schutzfristen vor und nach der Entbindung, einschließlich der Berechnung und Dauer des Mutterschaftsgeldes sowie die Bedingungen für dessen Ruhen. Paragraf 203 regelt die Auskunftspflichten einer Krankenkasse gegenüber zuständigen Behörden (u.a. die zu realisierende Kommunikation mit den Elterngeldstellen lokaler Behörden).


Die nachfolgende Tabelle 1 zeigt die aus den Texten der Paragrafen (Abb. 4) generierten Prozesse, Prozessziele und Arbeitsschritte.
| Paragraf | Prozess | Prozessziel | Arbeitsschritte |
| § 24i | Prüfung des Anspruchs auf Mutterschaftsgeld | Feststellen, ob eine weibliche Person Anspruch auf Mutterschaftsgeld hat. | • Arbeitsunfähigkeit prüfen • Anspruch auf Krankengeld prüfen • Schutzfristen nach § 3 MuSchG prüfen • Ende des Arbeitsverhältnisses prüfen • Mitgliedschaft in einer Krankenkasse prüfen • Mutterschaftsgeld gewähren oder ablehnen |
| § 24i | Berechnung des Mutterschaftsgeldes | Das Mutterschaftsgeld basierend auf dem Arbeitsentgelt berechnen. | • Arbeitsverhältnis prüfen • Heimarbeit prüfen • Kündigung nach § 17 Absatz 2 MuSchG prüfen • Durchschnittliches Arbeitsentgelt der letzten drei Monate ermitteln • Gesetzliche Abzüge berechnen • Mutterschaftsgeld berechnen |
| § 24i | Prüfung des Höchstbetrags des Mutterschaftsgeldes | Sicherstellen, dass das Mutterschaftsgeld den Höchstbetrag nicht überschreitet. | • Durchschnittliches Arbeitsentgelt ermitteln • Höchstbetrag von 13 Euro prüfen • Übersteigenden Betrag berechnen • Übersteigenden Betrag vom Arbeitgeber oder zuständiger Stelle zahlen lassen |
| § 24i | Mutterschaftsgeld für spezielle Fälle berechnen | Mutterschaftsgeld für Frauen in speziellen Fällen berechnen. | • Ende des Arbeitsverhältnisses prüfen • Mitgliedschaft in einer Krankenkasse prüfen • Andere Mitglieder identifizieren • Mutterschaftsgeld in Höhe des Krankengeldes gewähren |
| § 24i | Festlegung des Zahlungszeitraums des Mutterschaftsgeldes | Den Zahlungszeitraum des Mutterschaftsgeldes festlegen. | • Voraussichtlichen Entbindungstag ermitteln • Zeitraum von 6 Wochen vor Entbindung berechnen • Zeitraum von 8 Wochen nach Entbindung berechnen • Mutterschaftsgeld für den berechneten Zeitraum zahlen |
| § 24i | Prüfung der Verlängerung des Zahlungszeitraums | Den Zahlungszeitraum bei besonderen Umständen verlängern. | • Frühgeburt prüfen • Mehrlingsgeburt prüfen • Behinderung des Kindes prüfen • Zahlungszeitraum auf 12 Wochen nach Entbindung verlängern |
| § 24i | Anpassung des Zahlungszeitraums bei vorzeitigen Entbindungen | Den Zahlungszeitraum bei vorzeitigen Entbindungen anpassen. | • Vorzeitige Entbindung prüfen • Nicht in Anspruch genommenen Zeitraum ermitteln • Zahlungszeitraum entsprechend verlängern |
| § 24i | Prüfung der Zahlung des Mutterschaftsgeldes bei neuem Arbeitsverhältnis | Sicherstellen, dass das Mutterschaftsgeld bei neuem Arbeitsverhältnis korrekt gezahlt wird. | • Beginn des Arbeitsverhältnisses prüfen • Schutzfristen prüfen • Mutterschaftsgeld von Beginn des Arbeitsverhältnisses an zahlen |
| § 24i | Prüfung des Ruhens des Anspruchs auf Mutterschaftsgeld | Feststellen, ob der Anspruch auf Mutterschaftsgeld ruht. | • Erhalt von beitragspflichtigem Arbeitsentgelt prüfen • Erhalt von Arbeitseinkommen prüfen • Erhalt von Urlaubsabgeltung prüfen • Anspruch auf Mutterschaftsgeld ruhen lassen |
| § 203 | Prüfung der Datenübermittlung Mutterschaftsgeld | Sicherstellen, dass die Krankenkasse die notwendigen Angaben zum Mutterschaftsgeld an die zuständige Behörde übermittelt. | • Prüfen, ob die Mutter Elterngeld beantragt hat • Prüfen, ob die Mutter in die Datenübermittlung eingewilligt hat • Prüfen, ob die Krankenkasse über die Einwilligung informiert wurde • Übermitteln der Angaben zum Mutterschaftsgeld, wenn alle Bedingungen erfüllt sind |
| § 203 | Sicherstellung der elektronischen Datenübermittlung | Gewährleisten, dass alle Datenübermittlungen elektronisch und verschlüsselt erfolgen. | • Prüfen, ob die Aufforderung zur Datenübermittlung elektronisch erfolgt • Prüfen, ob die Übermittlung der Daten elektronisch erfolgt • Sicherstellen, dass die Datenübermittlung verschlüsselt ist |
| § 203 | Festlegung und Genehmigung des Übertragungswegs und Verfahrens | Sicherstellen, dass der Übertragungsweg und die Einzelheiten des Übertragungsverfahrens festgelegt und genehmigt werden. | • Festlegen des Übertragungswegs • Festlegen der Einzelheiten des Übertragungsverfahrens • Einholen der Genehmigung durch das Bundesministerium für Gesundheit • Einholen der Genehmigung durch das Bundesministerium für Familie, Senioren, Frauen und Jugend |
Dem LLM gelingt es, aus den Ausgangstexten der beiden Paragrafen eine semantisch tiefe und umfassende Ableitung zu erstellen.
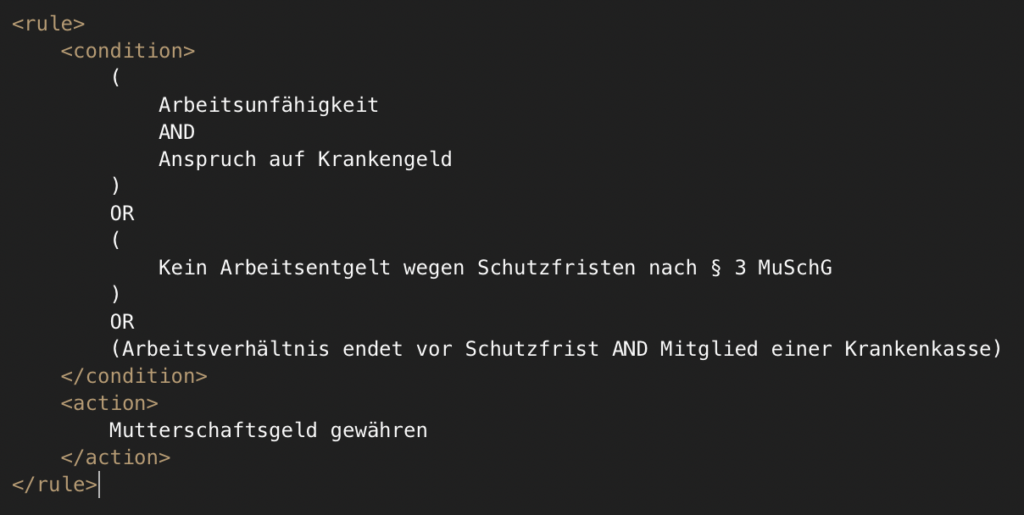
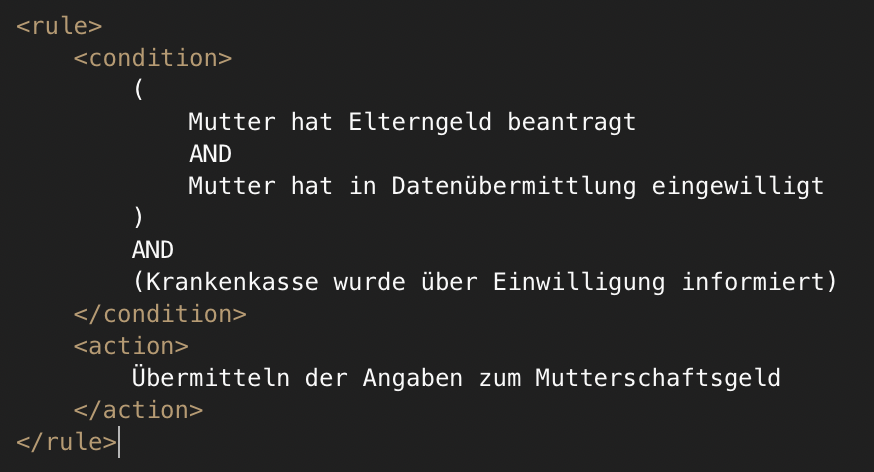
Zusätzlich werden für jeden Prozess die Geschäftsregeln in Form von BRML „Pseudo-Code“ generiert. Abbildung 5 zeigt das BRML-XML zum Prozess „Prüfung des Anspruchs auf Mutterschaftsgeld“ und Abbildung 6 zum Prozess „Prüfung der Datenübermittlung Mutterschaftsgeld“. Die BRML unterstützt im weiteren Verlauf bei der Implementierung automatisierter Prozesse, indem sie für Entwickler die zu realisierende fachliche Logik strukturiert.
Integration in einem Gesamtmodell
Anschließend werden die generierten Inhalte in einer Neo4j Datenbank konsolidiert, so dass ein zusammenhängendes Modell entsteht. Aufgrund des flexiblen No-SQL Ansatzes der Graphen-Datenbank ist die Integration der Ergebnisse ohne Einschränkungen durch ein starres Meta-Modell möglich. Klassische Werkzeuge des Architekturmanagement besitzen in der Regel ein festes Meta-Modell und müssen – wenn es überhaupt möglich ist – an individuelle Daten-Strukturen angepasst werden. Das ist bei einer No-SQL DB wie Neo4j nicht erforderlich, unabhängig ob neue oder bisher unbekannte Entitäts- oder Beziehungstypen zu berücksichtigen sind. Abbildung 7 zeigt eine 3D Visualisierung des Knowledge Graph der Prozess-Entitäten und dessen semantische Beziehungen. Auf dieser Struktur werden in einem späteren Schritt u.a. grafentheoretische Analysen vorgenommen, um Optimierungsfragen zu beantworten.
Automatische Anreicherung durch logische Schlussfolgerung
Im nächsten Schritt wird das Modell durch logische Schlussfolgerungen erweitert. Dafür kommen u.a. „kleine“ LLMs im lokalen Netzwerk zum Einsatz. Durch die vorhergehende Integration bieten die Daten jetzt genug „inhaltliche Tiefe“ (s. Abbildung 7), so dass mit Hilfe des vorliegenden Knowledge Graphen implizit im Modell enthaltenes Wissen automatisch herausgearbeitet werden kann. Dazu verwenden wir u.a. das Modell Mistral Small mit 24 Milliarden Parametern. Der Vorteil „kleinerer“ LLMs ist, dass sie auf Standard-Hardware zu geringen Kosten (< 5.000 Euro) produktiv im Behörden-, Sozialversicherungs- bzw. Unternehmensumfeld On-Premises einsetzbar und oftmals unter Open Source Lizenz verfügbar sind. Für das Beispiel wurden alle SGB V Prozesse mit Hilfe des LLM gruppiert und zu einem hierarchischen Prozesshaus zusammengefasst. Das LLM erkennt sinnvolle Gruppierungen, bündelt Unterprozesse, benennt übergeordnete Prozesse und beschreibt den Inhalt in einer auch für Nicht-Juristen verständlichen Sprache. Tabelle 2 zeigt einen Auszug aus dem Prozesshaus mit den Prozessen von § 24i und § 203.
| Hauptprozess | Beschreibung | Unterprozesse |
| Mutterschaftsgeldverwaltung | Der Geschäftsprozess „Mutterschaftsgeldverwaltung“ umfasst die Prüfung des Anspruchs auf Mutterschaftsgeld, die Berechnung und Anpassung des Mutterschaftsgeldes sowie die Festlegung und Verlängerung des Zahlungszeitraums. Ziel ist es, sicherzustellen, dass weibliche Mitglieder während der Schutzfristen vor und nach der Entbindung korrekt unterstützt werden. | • Prüfung des Anspruchs auf Mutterschaftsgeld • Berechnung des Mutterschaftsgeldes • Prüfung des Höchstbetrags des Mutterschaftsgeldes • Mutterschaftsgeld für spezielle Fälle berechnen • Festlegung des Zahlungszeitraums des Mutterschaftsgeldes • Prüfung der Verlängerung des Zahlungszeitraums • Anpassung des Zahlungszeitraums bei vorzeitigen Entbindungen • Prüfung der Zahlung des Mutterschaftsgeldes bei neuem Arbeitsverhältnis • Prüfung des Ruhens des Anspruchs auf Mutterschaftsgeld |
| Elektronische Datenübermittlung Mutterschaftsgeld | Der Geschäftsprozess „Elektronische Datenübermittlung Mutterschaftsgeld“ umfasst die Prüfung der Datenübermittlung, die Sicherstellung der elektronischen und verschlüsselten Datenübermittlung sowie die Festlegung und Genehmigung des Übertragungswegs und Verfahrens. Ziel ist es, eine sichere und rechtssichere Übermittlung von Mutterschaftsgeldinformationen zwischen Krankenkassen und zuständigen Behörden im Rahmen des Elterngeldverfahrens zu gewährleisten. | • Prüfung der Datenübermittlung • Sicherstellung der elektronischen Datenübermittlung • Festlegung und Genehmigung des Übertragungswegs |
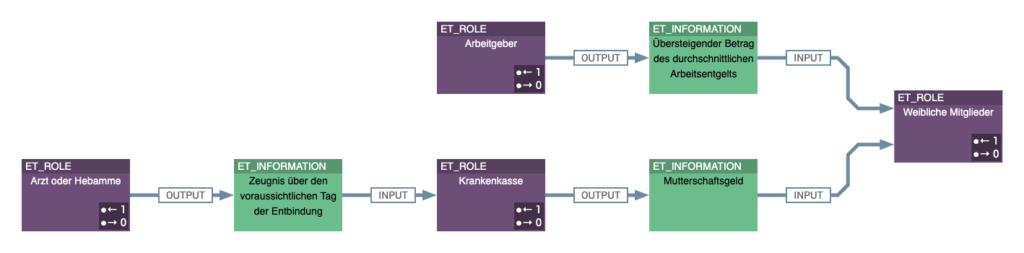
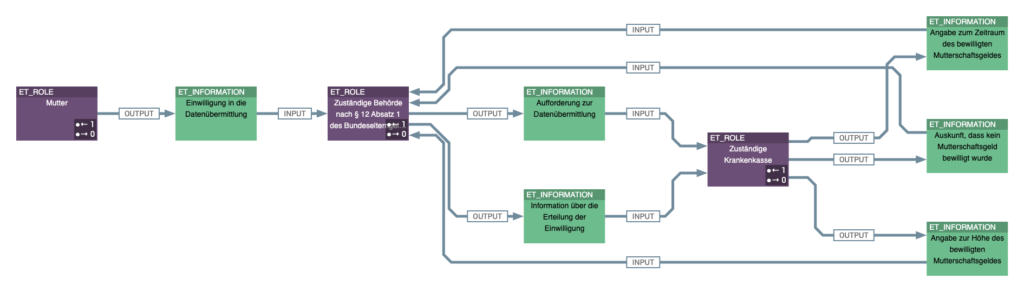
Weiterhin werden die an Prozessen beteiligten Rollen bzw. Organisationseinheiten (z.B. Krankenkassen, Meldebehörden, Ärzte, Apotheken etc.) und ausgetauschten Informationen (z.B. Elterngeldantrag) für jeden Paragraf ermittelt und im Basis-Knowledge-Graph ergänzt. Dies ermöglicht u.a. die Analyse, welche Organisationsobjekte bei der Prozessausführung miteinander kommunizieren und welche Informationen sie austauschen. Abbildung 8 zeigt die fachlichen Rollen- und Informations-Fluss-Beziehungen für § 24i und Abbildung 9 für § 203 SGB V.
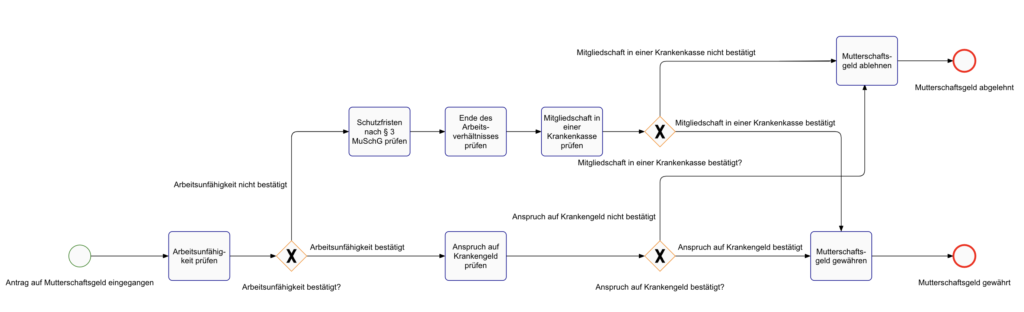
Zusätzlich werden für jeden Prozess BPMN-Diagramme auf Basis der Inhalte des Knowledge-Graph generiert. Im vorhergehenden Schritt (s. Tabelle 1) haben wir gezeigt, dass das LLM zu Prozessen die zugehörigen Arbeitsschritte ermittelt. Diese sind zunächst jedoch nur sequenziell. Mit Hilfe des LLM entsteht aus dem sequenziellen Ablauf ein BPMN-Diagramm, indem alternative Pfade antizipiert und zu einem über Gateways verzweigten Sequenzfluss zusammengefügt werden. Durch die Kombination der Arbeitsschritte und der BRML entstehen detaillierte BPMN-Diagramme. Abbildung 10 zeigt das Diagramm des Prozesses „Prüfung des Anspruchs auf Mutterschaftsgeld“ abgeleitet aus dem Text des § 10 SGB V Absatz 1:
„Weibliche Mitglieder, die bei Arbeitsunfähigkeit Anspruch auf Krankengeld haben oder denen wegen der Schutzfristen nach § 3 des Mutterschutzgesetzes kein Arbeitsentgelt gezahlt wird, erhalten Mutterschaftsgeld. Mutterschaftsgeld erhalten auch Frauen, deren Arbeitsverhältnis unmittelbar vor Beginn der Schutzfrist nach § 3 Absatz 1 des Mutterschutzgesetzes endet, wenn sie am letzten Tag des Arbeitsverhältnisses Mitglied einer Krankenkasse waren.“
Dem LLM gelingt es, auf Basis der Aktivitäten und der Beschreibung den grundsätzlichen Prozessverlauf zu generieren, jedoch werden nicht alle XOR-Verzweigungen korrekt dargestellt. Das LLM hat Schwierigkeiten die verschachtelte juristischen Sprache korrekt aufzulösen. Dennoch liefert es ein gutes Grundgerüst als Ausgangspunkt für die BPMN-Modellierung, welches durch eine kurze Qualitätssicherung in ein valides BPMN-Diagramm überführt werden kann. Die BPMN-Modellierung wird dadurch beschleunigt, da nicht mit einem „leeren Blatt“ begonnen werden muss, sondern eine Basis des zu modellierenden Prozesses automatisch bereitgestellt wird.
Ergänzung um (ggf. vertrauliche) Inhalte
Bis zu diesem Punkt basieren die Ergebnisse ausschließlich auf den Texten des SGB V. Weiter steigern lässt sich der Wert der Facharchitektur, wenn zusätzliche Texte das Modell ergänzen. Um zu demonstrieren, wie individuelle Ergänzungen im Modell eingefügt werden, verwenden wir einen Auszug aus dem Dokument „Grundsätze für das Meldeverfahren mit den Elterngeldstellen nach § 203 Abs. 3 SGB V“ des GKV-Spitzenverbands [9]. Unter der (fiktiven) Einschränkung, dass das Dokument vertraulich zu behandeln ist, kommt für die Bearbeitung nur das lokal verfügbare LLM zum Einsatz (das Dokument ist selbstverständlich nicht vertraulich und kann im Internet eingesehen werden). Exemplarisch wird aus dem Kapitel „Automatisiertes Meldeverfahren“ das Unterkapitel „Allgemeines“ analysiert und im Modell ergänzt. Abbildung 11 zeigt den unstrukturierten Ausgangstext und Abbildung 12 die generierten Ergänzungen.


RAG-basierte Analyse
Der Knowledge-Graph ermöglicht die Analyse individueller Szenarien und deren prozessualer und logischer Zusammenhänge, so dass umgangssprachlich formulierte Anwendungsfälle hinsichtlich betroffener Prozesse, Geschäftsregeln und operativer Zusammenhänge einfach zu betrachten sind. Architekten können mit dem Modell individuelle Fragestellungen direkt mit Facharchitekturinhalten abgleichen. Zum Beispiel lässt sich ein neuer Referentenentwurf eines Gesetzes hinsichtlich der Auswirkungen auf fachliche Prozesse, Arbeitsschritte und Geschäftsregeln mit geringem Aufwand bewerten.
Abbildung 13 zeigt eine freie Anfrage zum Thema „Geldleistung bei Mutterschaft beziehen“. Der gesamte Informationskorpus (im Beispiel SGB V und ergänzte individuelle Dokumente) wird durch die Unterstützung des Knowledge Graph effizient durchsucht. Im Beispiel erfolgt zunächst die Auswertung der gesamten Datenbasis für die Eingabe „Geldleistung“. Durch Konkretisierung der Abfrage um den Bezug zum Mutterschaftsgeld wird die Analyse auf diesen Bereich fokussiert. Das Inferencing der Abfrage erfolgt vollständig lokal, im Beispiel auf einem MacBook Pro mit M1 Prozessor. Das Video der Abfrage wurde in der Ausführungsgeschwindigkeit nicht verändert. Der hybride Ansatz ermöglicht es, Analysen bereits mit Standardhardware einer breiten Nutzerbasis datenschutzfreundlich zur Verfügung zu stellen.
Neben dem Blick auf die individuellen Prozesse ermöglicht der Knowledge-Graph, in Zusammenarbeit mit dem LLM, die Auswertung prozessübergreifender Zusammenhänge. Für den Anwendungsfall „Bearbeitung von Mutterschaftsgeld / Elterngeld“ ermittelt das LLM, welche Prozesse beteiligt sind und welche Vorgänger- und Nachfolgerbeziehungen zwischen ihnen vorliegen. Da es sich bei Verwaltungsabläufen häufig um adaptive, langlaufende und flexibel miteinander verbundene Prozesse handelt, verwenden wir für die Generierung des Gesamtüberblicks eine an CMMN angelehnte Darstellung. Diese ist zur Visualisierung des Gesamtbildes besser geeignet als BPMN. Abbildung 14 zeigt die Prozesszusammenhänge des Anwendungsfalls generiert als „CMMN-artiges“ Diagramm, welches automatisch aufbereitet wird.
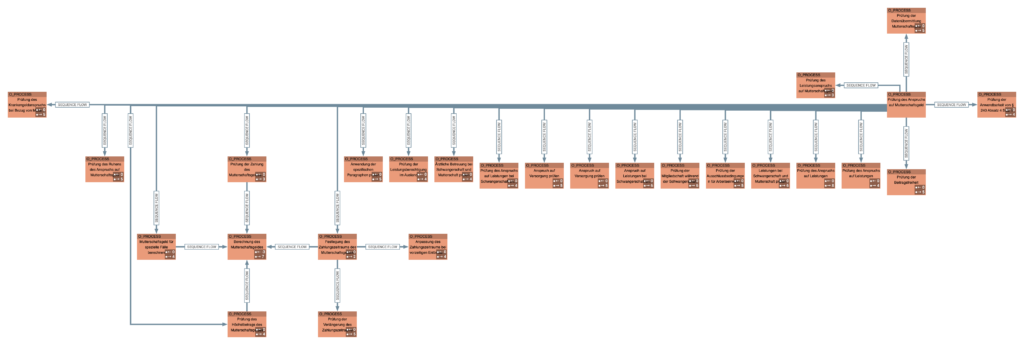
Das Modell hat auf Basis der Ausgangsdaten „gelernt“, welche Inhalte für die Bearbeitung eines Anwendungsfalls in welcher Reihenfolge relevant sind. Dadurch kann das Modell genutzt werden, um Architekturfragen ganzheitlich und schnell zu beantworten. Neben den im Beitrag gezeigten unstrukturierten Texten lassen sich zusätzlich Inhalte aus Modellierungswerkzeugen und operativen Datenquellen im Knowledge Graph ergänzen (mehr dazu unter „Leitfaden zum Aufbau einer integrierten Enterprise Architektur“).
Fazit
Die manuelle Erstellung und Pflege von Architekturmodellen ist aufwendig und ressourcenintensiv. Generative Sprachmodelle und Künstliche Intelligenz (KI) bieten vielversprechende Lösungsansätze, um weniger wertschöpfende (aber leider zur Datenerfassung notwendige) Tätigkeiten zu automatisieren.
Durch den Einsatz von LLMs ergeben sich folgende Vorteile:
- Reduzierung des Aufwands im Modellmanagement durch automatische Generierung auf Basis unstrukturierter Texte mit Large Language Models (LLMs)
- Integration eigener Daten durch KI und maschinellem Lernen
- Kontinuierliche Pflege bestehender Architekturmodelle vereinfachen und beschleunigen
Es bestehen aber auch Herausforderungen:
- Die von LLMs erzeugten Inhalte sind in der Größenordnung 85…90% korrekt. Qualitätssicherung und Kontrolle sind deshalb bis auf weiteres unverzichtbar. Die Tatsache, dass KI-Anwendungen im Architekturmanagement beindruckende Ergebnisse erzielen, darf nicht dazu verleiten zu glauben, „die KI hat immer recht“. Menschliches Mitdenken ist erwünscht und erforderlich.
- Für besonders rechenintensive Aufgaben, wie in unserem Beispiel die initiale Erstellung des Knowledge Graphen, benötigen wir aktuell noch Cloud-basierte Dienste. Das Thema Datenschutz und vertrauliche Inhalte bleibt ein kritischer Aspekt. Aber die vollständig lokale Bearbeitung rückt in greifbare Nähe. Mit der RTX 6000 hat Nvidia ein Hardwareangebot, welches für größere Organisationen durchaus interessant ist und viele der im Beispiel extern durchgeführten Berechnungen bereits lokal ausführen kann. Meine Prognose ist, dass wir in einem Jahr in der Lage sind das vorgestellte Beispiel vollständig lokal zu berechnen.
Es wird spannend sein zu sehen, wie sich diese Technologie weiterentwickelt und in der Praxis bewährt. Bereits heute ist erkennbar, dass sie vielversprechende Ergebnisse liefern wird.
Beantworten wir abschließen die oben gestellten Ausgangsfragen:
Ist es möglich, mit der automatischen Generierung eines Architektur-Modells auf Basis unstrukturierter Textdaten eine signifikante Reduzierung des Aufwandes der Modellerstellung zu erreichen?
Die Umsetzung des SGB V Textes in einen Knowledge-Graphen erforderte zum Aufbau des Basismodells eine Rechenzeit von rund 5 Stunden. Dabei wurden aus 694 Paragrafen 5100 Prozesse, 16988 Arbeitsschritte und 5100 Geschäftsregeln abgeleitet. Nicht alle Prozesse beschreiben operativ relevante Tätigkeiten (z.B. wurden aus dem SGB V auch Prozesse der Gremienarbeit legislativ tätiger Einheiten generiert). Die Mehrheit der erzeugten Inhalte (> 70%) betreffen operativ relevante Tätigkeiten im betrachteten Fachgebiet.
Unter der (optimistischen) Annahme, dass zur manuellen Ermittlung je Prozess mindestens 1/8 Personentag benötigt wird, ergibt sich ein Gesamtaufwand von rund 450 Personentagen für die Aufnahme ohne KI-Unterstützung.
Demgegenüber erfordert die KI gestützte Erfassung eine Qualitätssicherung der generierten Ergebnisse, da – zumindest aktuell – kein LLM fehlerfreie Ergebnisse liefert. Wenn wir davon ausgehen, dass 80% der generierten Inhalte einer kurzen Überarbeitung unterzogen werden müssen, dann ergibt sich bei kalkulatorischen 15 Minuten je Prozess inkl. der initialen Generierungszeit des SGB V ein Aufwand von rund 90 Personentagen mit KI-Unterstützung. Dies ist eine Annahme mit hoher Sicherheitsmarge, die in den betrachteten Beispielen deutlich schneller erledigt war. Vergleichen wir beide Ansätze, so ergibt sich ein Produktivitätsgewinn bei der KI-gestützten Erstellung einer Facharchitektur von mindestens 80 %.
Gelingt es, das Architekturmodell durch die Nutzung individueller Inhalte besser an der eigenen Organisation auszurichten, anstatt nur „KI generierte Allgemeinplätze“ zu erhalten?
Durch die Integration eigener (ggf. vertraulicher Inhalte) ist es möglich, die Ergebnisse der KI-Generierung schnell und gezielt an die eigenen Gegebenheiten anzupassen. Gegenüber einer manuell durchgeführten Modellbildung ergibt sich der vorhergehend erläuterte Effizienzvorteil. Wichtiger ist aber, dass die Inhalte der eigenen Organisation genutzt werden und nicht ein externes LLM allgemeine Ergebnisse liefert, die die individuelle Situation nicht widerspiegeln. Der vorgestellte hybride Ansatz ermöglicht eine datenschutzfreundliche Vorgehensweise, so dass auch vertrauliche interne Unterlagen in die Modellerstellung einbezogen werden können. Cloud-Anbieter können das nicht leisten.
Können strategische, organisatorische und technische Entscheidungen mit Hilfe eines auf diesem Weg erstellten Modells vereinfacht und beschleunigt werden?
Durch die Bereitstellung umfangreicher Analysen auf Basis des Knowledge-Graphen ist es möglich, schnell und mit geringem Aufwand strategische, organisatorische und technische Fragen zu beantworten. Zum Beispiel bietet ein generiertes Prozess-Informationsfluss-Diagramm einen Überblick zu organisatorischen und informationstechnologischen Schnittstellen, mit Bezug zu Anwendungsfällen und Prozessen. Selbstverständlich steht und fällt die Qualität der Analysen mit der Qualität des zugrundeliegenden Knowledge-Graphen. Ist diese gegeben, dann liefern sie eine ideale Basis, um Entscheidungen vorzubereiten und zu unterstützen.
Stehen wir vor einem grundlegenden Wandel in der Art und Weise, wie Facharchitekturen erstellt und „betrieben“ werden?
Ja. Es wird noch etwas dauern bis sich die Ansätze in der Breite durchsetzen, aber aufhalten lassen sie sich nicht. Der Weg dorthin wird über Zwischenstadien verlaufen, in denen automatisierte (generierende) und manuelle Techniken des Architekturmanagements parallel existieren. Meine Prognose ist, dass wir in in nächster Zeit „Architektur-Assistenten“ sehen, die den menschlichen Facharchitekten zur Seite stehen. Facharchitekten sollten sich bereits heute auf die neue Welt einstellen. Die Notwendigkeit KI-Wissen aufzubauen geht auch an ihnen nicht vorbei.
Ist die Zeit der klassischen Modellierungssoftware vorbei?
Auch hier ein klares ja, wenn das Ende auch nicht morgen bevorsteht. Für einige Zeit werden noch manuelle Arbeiten im Bereich der Erstellung von Facharchitekturen erforderlich sein, wie wir am Beispiel des generierten und zu bearbeitenden BPMN-Diagramms gesehen haben. Dafür wird (zunächst noch) spezialisierte Modellierungssoftware gebraucht. Der Fortschritt in der automatischen Generierung von Facharchitekturen, inklusive der Generierung fachlicher Diagramme zeigt aber deutlich, dass ihre Tage gezählt sind.
Architekten müssen sich dringend die Frage stellen: „Modellieren sie noch oder generieren sie schon?“
Quellen:
[1]: Exploring AI-driven approaches for unstructured document analysis and future horizons
[2]: AI Agents: Evolution, Architecture, and Real-World Applications
[4]: Machine learning operations
[6]: Design of a Tool for Requirements Extraction from Legal Documents
[7]: An overview of information extraction techniques for legal document analysis and processing
[8]: Transforming government through digitization
[9]: Grundsätze für das Meldeverfahren mit den Elterngeldstellen nach § 203 Abs. 3 SGB V