Are you already generating or still modeling?
Law2Logic
Creating Business Architectures with AI
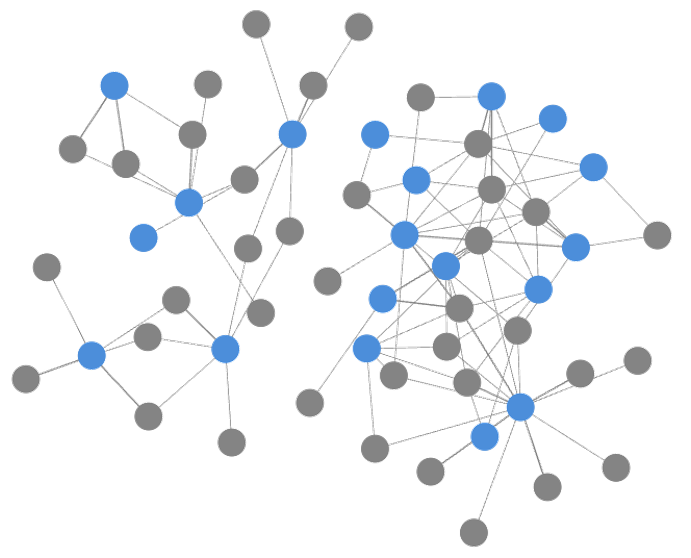
Is it possible to create a domain architecture out of unstructured text documents using generative Large Language Models? Based on an example and fictitious health insurance company, we examine the opportunities and challenges of automatically generating architecture content.
Business Architectures are an important building block for the management of public authorities, social insurance providers, and private companies. They support strategic, operational, and IT decisions based on a sound information fundament. A good Business Architecture provides the foundation for identifying and effectively managing interrelationships and dependencies in modern organizations. However, the challenge is that the initial setup and long-term maintenance can create considerable effort. Do recent advances in generative Artificial Intelligence (AI) and Large Language Models (LLM) help?
Today, Business Architectures are usually created manually. Setting them up and maintaining them involves a lot of effort. This effort would be better spent improving the organization rather than on the (unfortunately) necessary capturing of content for the architecture model. This offers considerable leverage to unlock potential. Specifically, the following questions arise:
- Is it possible to achieve a significant reduction in the effort required for model creation by automatically generating an architectural model based on unstructured text data?
- Is it possible to better tailor the architecture model to one’s own organization by using individual content, instead of just receiving „AI-generated platitudes“?
- Can strategic, organizational and technical decisions be simplified and accelerated with the help of a generated model?
- Are we facing a fundamental change in the way Business Architectures are created and “operated”?
- Is the time of classic modeling tools over?
Let’s have a look at the current situation.
Unstructured data is the norm in government agencies, social security institutions, and private companies. Approximately 90% of all information is unstructured, challenging traditional methods of automated processing. This leads to inefficiencies and the risk of information loss [1]. The integration of artificial intelligence, machine learning, and graph-based documentation enables the extraction and processing of content from disparate sources such as work instructions, process descriptions, legal documents, medical records, and annual financial statements . This paves the way for automated and data-driven architectural documentation [1][2]. Through automatic extraction, models can be easily developed that reflect real-world entities and their relationships [3][4] and adapt to organizational changes. Dynamic adaptation is crucial, because the continuous maintenance of (business) architectures, in particular, generates considerable effort. Reality changes at a rate that makes it almost impossible to keep a large model up-to-date manually. The use of LLMs to extract architecture-relevant content from unstructured documents is therefore a natural choice.
LLM combination in a hybrid approach
Data protection concerns deter many users to send potentially confidential data to cloud-based services. But developments in the field of AI over the past 12 months have helped to exploit the potential of local generative architectural modeling. A hybrid approach, in particular, paves the way of combining the capabilities of Large Language Models „in the cloud“ (>100 billion model parameters) with the privacy-friendly use of „smaller“ LLMs operating within local networks (see Figure 1).
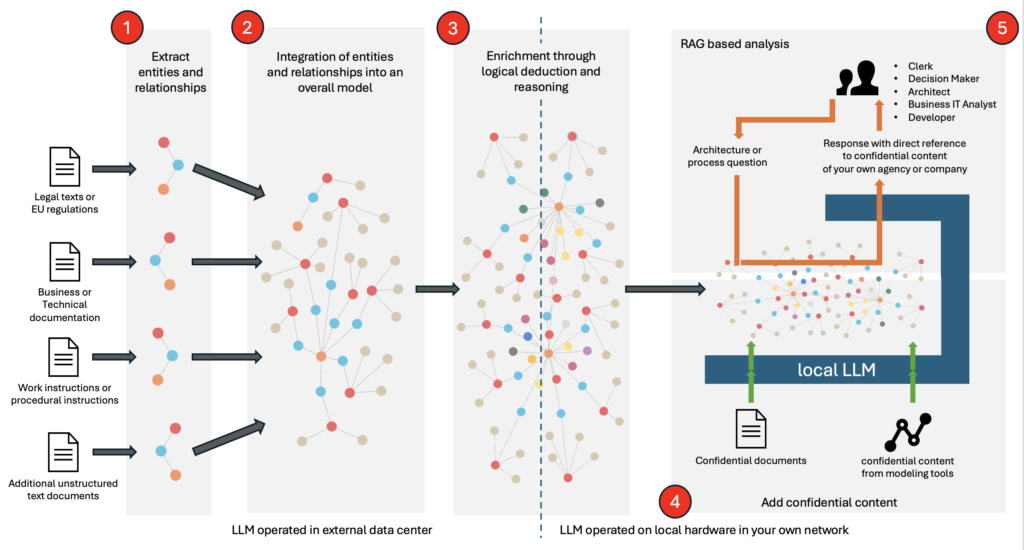
1. Determination of entities and relationships
The first step in generating a domain architecture using the hybrid approach consists in analyzing the unstructured base texts, which are not critical from a data protection perspective, but already provide a good overview of the respective domain. For this purpose, an LLM in the cloud is used. The LLM scans the texts for entities and relationships relevant to the domain. Entities include people, organizations, places, or concepts. Relationships describe the interactions or connections between the entities. This creates a basic ontology for the domain under consideration.
2. Integration within an overall model
In the second step, the extracted entities and relationships are combined into a graph model. A graph is a data structure consisting of nodes (entities) and edges (relationships). This creates a logical representation of the linked information extracted from the unstructured text. This model serves as the foundation for further processing, enrichment, and analysis. This step is also performed using the large LLM in the cloud to ensure high accuracy.
3. Automatic enrichment through logical reasoning
In the third step, the graph model is enriched through logical deduction and reasoning. Information is automatically derived from existing data that is implicitly contained in the source text but is only recognized by a language model through logical reasoning. This enrichment expands the database to enable comprehensive evaluations and analyses.
4. Addition of confidential content
In the fourth step, confidential content is added to the model. Local processing ensures that this content remains protected. This includes both content from unstructured texts and structured content from (architectural) modeling tools (e.g., Adonis, ARIS, BIC, Enterprise Architect , LeanIX , Signavio , etc.). Processing is performed exclusively with a „small“ LLM operated within the company’s own network.
This allows to consider the data protection requirements of an organization without compromising confidential data. Unlike solutions that „only“ provide general answers, adding confidential government-, social security-, or company-specific content enables significantly more precise architectural analyses. Simply put, the query „Create an order- to -cash process“ doesn’t yield a general answer based on ChatGPT or other LLMs. Instead, the specific content is used, generating a customized process. Only then does a model emerge that truly describes your individual organization.
5. RAG-based analysis
The fifth and final step consists of the practical application of the domain architecture model. A modification of the Retrieval Augmented Generation (RAG) method is used for this purpose. RAG combines the strengths of information retrieval and text generation to generate precise and relevant answers to user questions. By using a local „Retrieval LLM,“ the created model can be queried based on the user’s own content in a privacy-friendly manner.
Example: Law2Logic – Business architecture generated from law text
Remark: The following examples are based on the text of the German Social Code Book V – Statutory health insurance, which summarizes almost all provisions of health insurance in Germany. Due to the German base content, some of the generated information within the figures below are in German. Textual examples are translated where possible. However, the presented methodology for extracting a domain architecture from unstructured texts can be carried out in any language supported by the LLM. But don’t worry… we’re here to walk you through the material and explain everything in detail. Just reach out at info@magaseen.de to set up a live interaction.
Politicians are pressing hard to implement digital solutions in public authorities, administrations, and social security systems. Laws form the business fundament for this modernization. Therefore, legal texts are a suitable starting point for investigating the practical feasibility of generating a Business Architecture from unstructured texts using the hybrid approach. In addition to their political significance, law texts are characterized by dense language and complex interpretation possibilities. Legal texts therefore pose a challenge for automated analysis and require advanced methods for extracting machine-readable structures [6][7][8].
As an example, we will use the German Social Code Book V – Statutory health insurance (SGB V) to create a Business Architecture model. This book describes the legal framework within health insurances, regulatory authorities, hospitals, physicians, pharmacies, nursing facilities, care centers, and other medical service providers operate in Germany. It provides the framework for deriving a Business Architecture in the area of medical service provision.
Of course, in many cases, additional (and often confidential) content must be added to create an individual architecture model. To simulate this scenario, we add parts of the document „Principles for the reporting procedure with the Parental Allowance Offices according to § 203 Section 3 SGB V“ of the GKV-Spitzenverband (National Association of Statutory Health Insurance Funds) and the add extracted results to the Business Architecture model [9].
Due to the volume of the generated data, this article only presents sample results. The entire Knowledge Graph of the 694 SGB V paragraphs is available online in a web portal for further analysis. If you are interested in online access to this dataset, please send a short email from your government, social security, or company account to info@magaseen.de .
Extraction of entities and relationships of SGB V
The content of SGB V is available on the website „Gesetze im Internet” published by the German Federal Ministry of Justice. In addition to the text version, machine-readable exports are also available, of which the XML version is used for extracting the entities and relationships in our case (Figure 2 shows an excerpt).
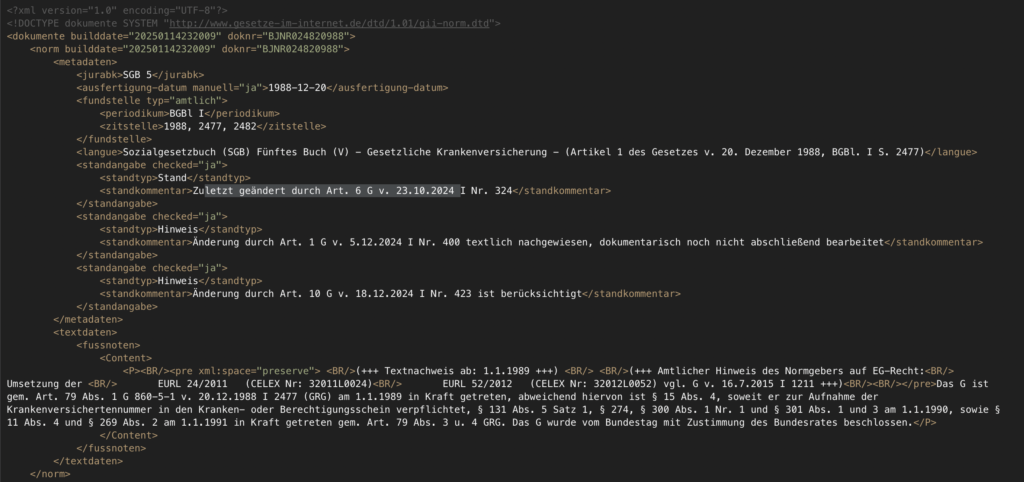
The base data is generated using the European language model „Mistral Large,“ which currently has 123 billion parameters and has been adapted to the specific requirements of legal analysis. The model is run at the Mistral AI data center. This ensures compliance with European data protection laws and no data leakage to American or Chinese providers (even though the content of this example is freely available and therefore not critical in this regard).
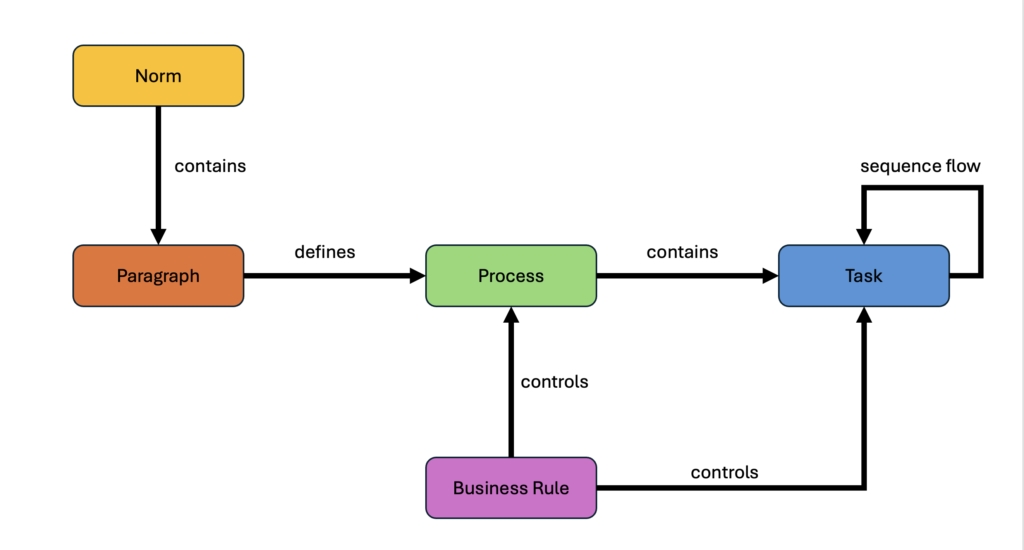
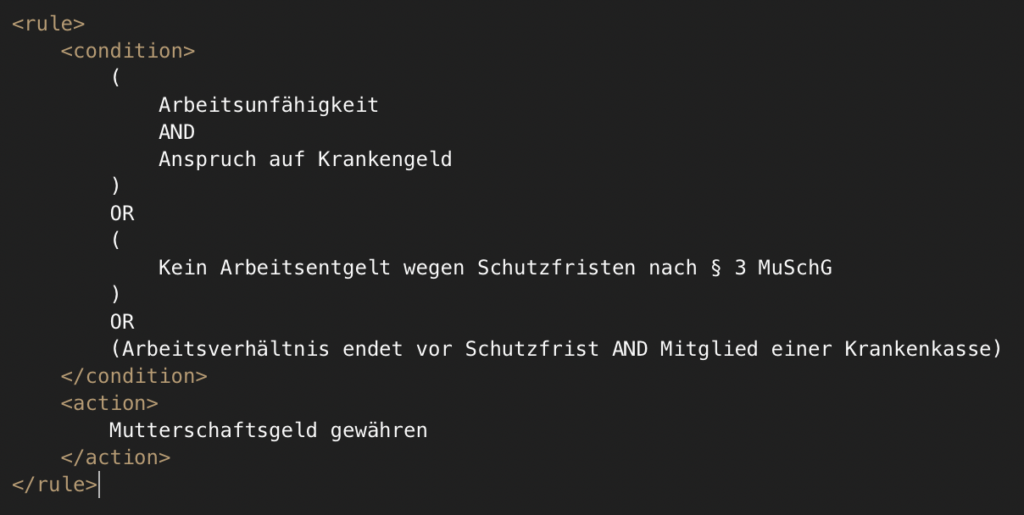
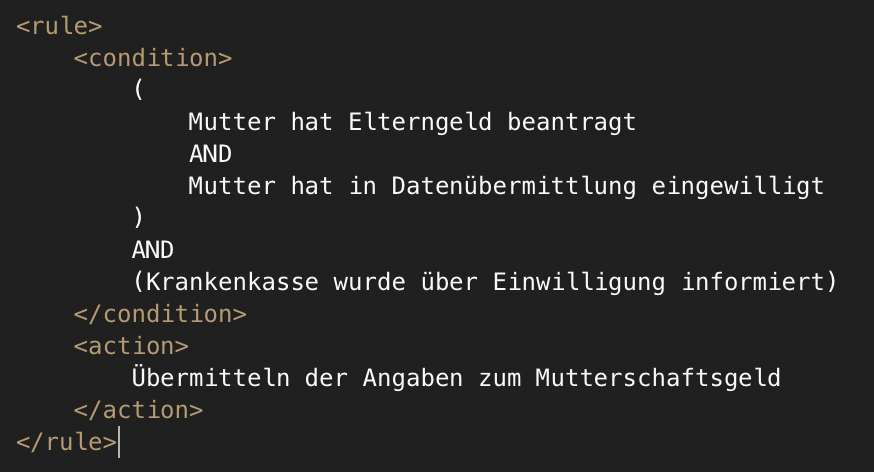
For each paragraph, the LLM extracts the implicitly contained processes, the tasks per process, the sequence flow of the tasks, and the logical business rules expressed in the Business Rule Markup Language (BRML). BRML is a neutral exchange format that describe business rules in XML.
This results in an initial Knowledge Graph with the following quantities:
- 1 Law (Norm)
- 694 Paragraphs,
- 5100 Processes,
- 16988 Tasks and
- 5100 Business Rules
Figure 3 shows the relationships between the entities in a simplified meta-model.
All results are generated entirely using the LLM and algorithms based on the content extracted from the XML file of the SGB V. No content was manually added or modified. This includes minor deviations and misinterpretations of the LLM, so the results presented allow an assessment of the generation quality.
The results of the following paragraphs are presented in more detail below:
- § 24i – Maternity allowance -> as an example for the derivation of operational business architecture content
- § 203 – Reporting obligations for the payment of maternity allowance, parental allowance or childcare allowance -> as an example for the derivation of implementation-related technical architecture content
Figure 4 shows the source text of § 24i and § 203. Only this text was used for the entire generation.
§ 24i regulates the payment of maternity allowance to female members during the protection periods before and after childbirth, including the calculation and duration of maternity allowance, as well as the conditions for its suspension. § 203 regulates a health insurance fund’s duty to provide information to the relevant authorities (including the necessary communication with parental allowance offices at local authorities).


Table 1 shows the results generated from the texts of the example paragraphs (Fig. 4).
| Paragraph | Process | Process goal | Work steps |
| § 24i | Examination of entitlement to maternity benefit | Determine whether a woman is entitled to maternity benefit. | • Check incapacity for work • Check entitlement to sick pay • Check protection periods according to § 3 MuSchG • Check the end of the employment relationship • Check health insurance membership • Grant or refuse maternity benefit |
| § 24i | Calculation of maternity benefit | Calculate maternity benefit based on wages. | • Check employment relationship • Check home workingCheck termination according to § 17 Section 2 MuSchG • Determine average wages for the last three months • Calculate statutory deductions • Calculate maternity benefit |
| § 24i | Checking the maximum amount of maternity benefit | Ensure that maternity benefit does not exceed the maximum amount. | • Determine average wages • Check maximum amount of 13 euros • Calculate excess amount • Have the excess amount paid by the employer or the relevant authority |
| § 24i | Calculate maternity allowance for special cases | Calculate maternity allowance for women in special cases. | • Check the end of the employment relationship • Check health insurance membershipIdentify other members • Grant maternity benefit equal to sickness benefit |
| § 24i | Determination of the payment period for maternity benefit | Determine the payment period for maternity benefit. | • Determine the expected date of delivery • Calculate the period of 6 weeks before delivery • Calculate the period of 8 weeks after delivery • Pay maternity benefit for the calculated period |
| § 24i | Examination of the extension of the payment period | Extend the payment period in special circumstances. | • Check for premature birth • Check multiple births • Check the child’s disability • Extend payment period to 12 weeks after delivery |
| § 24i | Adjustment of the payment period in the event of premature births | Adjust the payment period for premature births. | • Check for premature delivery • Determine unused period • Extend the payment period accordingly |
| § 24i | Review of maternity benefit payment in the case of a new employment relationship | Ensure that maternity benefit is paid correctly when you start a new job. | • Check the start of the employment relationship • Check protection periods • Pay maternity benefit from the start of the employment relationship |
| § 24i | Examination of the suspension of the entitlement to maternity benefit | Determine whether the entitlement to maternity benefit is suspended. | • Check receipt of wages subject to contributions • Check receipt of income from employment • Check receipt of vacation pay • Suspending entitlement to maternity benefit |
| § 203 | Review of data transmission for maternity allowance | Ensure that the health insurance fund provides the necessary information regarding maternity benefit to the competent authority. | • Check whether the mother has applied for parental allowance • Check whether the mother has consented to the data transfer • Check whether the health insurance company has been informed about the consent • Submitting maternity benefit information if all conditions are met |
| § 203 | Ensuring electronic data transmission | Ensure that all data transmissions are electronic and encrypted. | • Check whether the request for data transmission is made electronically • Check whether the data is transmitted electronically • Ensure that data transmission is encrypted |
| § 203 | Determination and approval of the transmission method and procedure | Ensure that the method of transfer and the details of the transfer process are determined and approved. | • Specifying the transmission path Determine the details of the transfer procedure • Obtaining approval from the Federal Ministry of Health • Obtaining approval from the Federal Ministry for Family Affairs, Senior Citizens, Women and Youth |
The LLM succeeds in creating a semantically rich process and task derivation based on the source text of the two paragraphs. Additionally, the business rules of each process are generated in the form of BRML „pseudo-code.“ Figure 5 shows the BRML XML for the „Checking Entitlement to Maternity Benefit“ process, and Figure 6 the „Checking Maternity Benefit Data Transmission“ process. This BRML logic supports the implementation of automated processes by defining the business logic for developers.
Integration in an overall model
The generated content is then consolidated in a Neo4j graph database to create a coherent model. The flexible No-SQL approach of the database makes it possible to integrate the results without the restrictions of a rigid meta-model. Classic architecture modeling tools usually have a fixed meta-model that require a customization – if at all possible. This is not necessary with a No-SQL DB like Neo4j, regardless of whether new, previously unknown entity or relationship types need to be taken into account. The resulting Knowledge Graph serves as a basis for comprehensive architecture analyses. Figure 7 shows a 3D visualization of the process entities Knowledge Graph and their semantic relationships. In a later step, graph theory analyses are carried out on this structure in order to answer optimization questions.
Automatic enrichment through logical reasoning
In the next step, the model is extended through logical inferences. For this purpose, we use „small“ LLMs in the local network. Thanks to the previous integration, the data now offers sufficient „content depth“ (see Figure 7) so that, with the help of the existing graph structure, knowledge implicitly contained in the model can be automatically extracted. For this purpose, we use the Mistral Small model with 24 billion parameters. The advantage of „smaller“ LLMs is that they can operate on- premises with standard hardware at low cost (< 5,000 €) in government, social security, or private corporate network environments and are also often available with open-source license.
For the example, all SGB V processes were grouped and combined in a hierarchical process house. The LLM recognizes meaningful groupings, bundles sub-processes, labels higher-level processes, and creates a description that is understandable even to non-lawyers. Table 2 shows an excerpt of the grouping that covers § 24i and § 203.
| Main process | Description | Subprocesses |
| Maternity benefit administration | The „Maternity Benefit Management“ business process includes checking eligibility for maternity benefits, calculating and adjusting maternity benefits, and determining and extending the payment period. The goal is to ensure that female members receive proper support during the pre- and postnatal periods. | • Examination of entitlement to maternity benefit • Calculation of maternity benefit • Checking the maximum amount of maternity benefit • Calculate maternity allowance for special cases • Determination of the payment period for maternity benefit • Examination of the extension of the payment period • Adjustment of the payment period in the event of premature births • Review of maternity benefit payment in the case of a new employment relationship • Examination of the suspension of the entitlement to maternity benefit |
| Electronic data transmission of maternity allowance | The „Electronic Data Transmission for Maternity Allowance“ business process includes reviewing data transmission, ensuring electronic and encrypted data transmission, and determining and approving the transmission path and procedure. The goal is to ensure the secure and legally compliant transmission of maternity allowance information between health insurance funds and the relevant authorities within the framework of the parental allowance process. | • Checking data transmission • Ensuring electronic data transmission • Determination and approval of the transmission route |
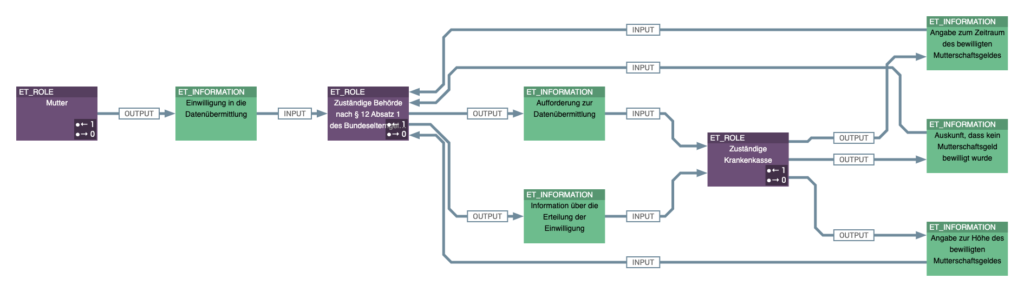
Furthermore, the roles or organizational units involved in the processes (e.g., health insurance companies, registration authorities, doctors, pharmacies, etc.) and the information exchanged (e.g., parental allowance applications) are determined for each paragraph and added to the basic Knowledge Graph. This opens up an overall analysis of which organizational objects communicate with each other during the execution of the processes and what information they exchange during this communication. Figure 8 shows the functional role and information flow relationships for § 24i, and Figure 9 for § 203 of the Social Code Book V.

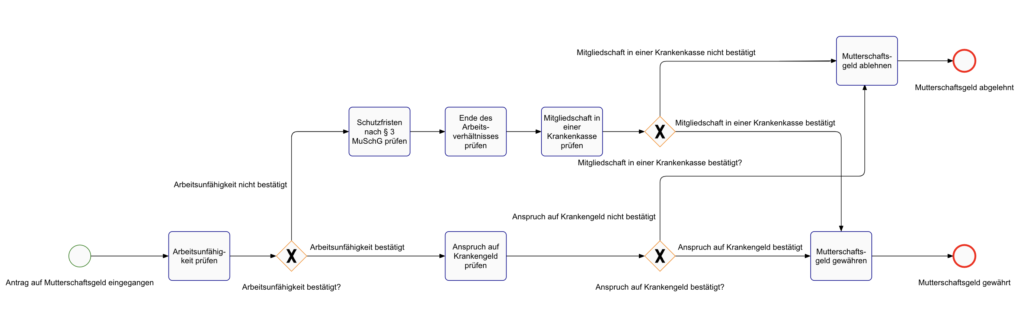
Additionally, BPMN diagrams are generated for each process based on the content of the Knowledge Graph. In the previous step, we showed that the LLM determines the tasks required to execute a process. However, these tasks are initially only connected in a sequential order. With the help of the LLM, a BPMN diagram is created from the sequential process by anticipating alternative paths and combining them into a sequence flow branched with gateways. By combining the tasks and the BRML, detailed BPMN diagrams emerge. Figure 10 shows the generated BPMN diagram of the process „Checking the entitlement to maternity allowance“ derived from the text of § 10 of the Social Code Book V, Section 1:
„Female members who are entitled to sick pay due to incapacity for work or who are not paid wages due to the protection period under § 3 of the Maternity Protection Act will receive maternity benefit. Women whose employment relationship ends immediately before the start of the protection period under § 3 Section 1 of the Maternity Protection Act will also receive maternity benefit if they were members of a health insurance fund on the last day of their employment relationship.“
The LLM succeeds in generating the basic process flow based on the tasks and the description, but not all XOR branches are correctly resolved. The LLM shows some difficulties in resolving the nested legal language correctly. Nevertheless, it provides a good starting point for BPMN modeling, which can be converted into a valid BPMN diagram through a brief quality assurance in a few seconds. This accelerates BPMN modeling because it is not necessary to start with a „blank slate“; instead, a basis for the process to be modeled is automatically provided. And this basis is grounded on the individual text documentation of the organization.
Addition of (possibly confidential) content
Up to this point, the results have been based exclusively on the texts of the SGB V. The benefit can be further increased by supplementing the model with information extracted from additional text. To demonstrate how individual additions can be incorporated into the model, we use an excerpt from the document “ Principles for the reporting procedure with the Parental Allowance Offices according to § 203 Section 3 SGB V “ of the GKV-Spitzenverband [9]. Under the (fictitious) restriction that this document is to be treated confidentially, only the locally available LLM is used for processing (the document is, of course, not confidential and can be viewed online). As an example, the subchapter „General“ from the chapter „Automated reporting procedure“ is analyzed and supplemented in the model. Figure 11 shows the unstructured source text and the additions generated in Figure 12.


RAG-based analysis
The knowledge graph enables the analysis of individual scenarios and their procedural and logical relationships, making it easy to examine colloquially formulated use cases with regard to affected processes, business rules, and operational relationships. Architects can use the model to compare individual questions with business architecture content. For example, a new draft of a bill can be evaluated with minimal effort with regard to its impact on business processes, work steps, and business rules.
Figure 13 shows a query on the topic of „receiving cash benefits for maternity.“ The entire information corpus (in the example, SGB V and supplemented individual documents) is efficiently searched with the support of the knowledge graph. In the example, the entire database for the input „cash benefit“ is evaluated first. By specifying the query to include the receipt of maternity benefit, the analysis is focused on this area. The inferencing for the query is performed entirely locally; in the example, on a MacBook Pro with M1 processor. The video has not been altered in terms of execution speed. The hybrid approach makes it possible to perform analyses in a privacy-friendly manner using standard hardware.
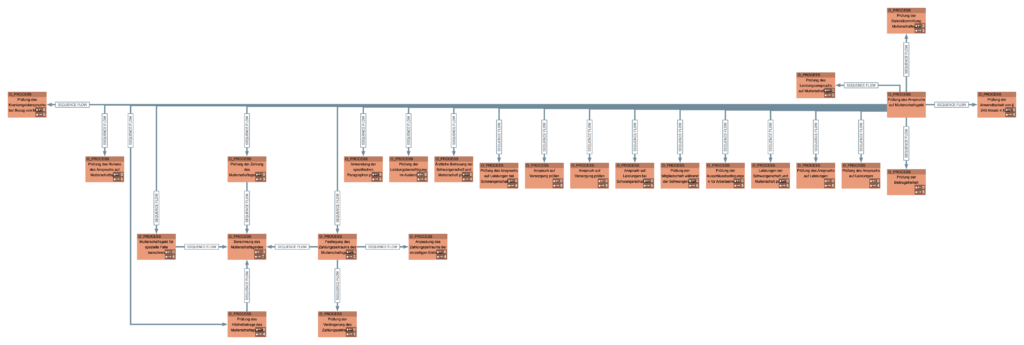
In addition to the analysis of single processes, the Knowledge Graph and the LLM enables the evaluation of overall process relationships. For the use case „Processing maternity/parental allowance,“ we determine which processes are involved and what their sequential relationships are. Since administrative processes are often adaptive, long-running, and flexibly interconnected, we use a CMMN-like representation to visualize the overall relations. This approach is better suited than BPMN. Figure 14 shows the process relationships identified by the LLM as a „CMMN-like“ diagram, which is automatically visualized.
Based on the initial data, the model has “learned” which content is relevant for processing a use case and in which order. This means that the model can be used to answer architectural questions holistically and quickly. Beside unstructured text, content from modeling tools and operational data sources can be added to the Knowledge Graph as well. The article „Guide to Building an Integrated Enterprise Architecture“ describes this approach in detail.
Conclusion
The manual creation and maintenance of architectural models is time-consuming and resource intensive. Generative Large Language Models and Artificial Intelligence offer promising solutions for automating less value-adding activities in the field of architecture management.
Advantages:
- Reducing the effort in model management through automatic generation based on unstructured texts using Large Language Models
- Integration of individual and potentially confidential data through local AI and machine learning implementations
- Simplify and accelerate continuous maintenance of architectural models
However, there are also open issues and challenges:
- The architecture content generated by LLMs is up to 85-90% correct. Quality assurance and control are therefore essential for the time being. The fact that AI applications in architecture management achieve impressive results should not mislead us to believe that „AI is always right.“ Human input is both still desirable and necessary.
- For computationally intensive tasks, such as the initial creation of the Knowledge Graph, we currently still require cloud-based services. Data protection and confidential content remain critical. But fully local processing is within reach. With the RTX 6000, Nvidia offers a hardware that is quite interesting for larger organizations and can already execute many of the calculations locally. My prediction is that in a year’s time, we will be able to run the presented example entirely local.
It will be exciting to see how this technology develops and proves itself in practice. However, it is already clear that it will deliver promising results.
Let us finally answer the initial questions posed above:
Is it possible to achieve a significant reduction in the effort required for model creation by automatically generating an architectural model based on unstructured text data?
Converting the SGB V text into a Knowledge Graph required approximately five hours of computing time to build the base model. 5,100 processes, 16,988 tasks, and 5,100 business rules were derived from 694 paragraphs. Not all processes describe operationally relevant activities (e.g., processes for committee work of legislative units were also generated from SGB V ). Nevertheless, most of the generated content (> 70%) refers to operationally relevant activities in the subject area.
Under the (optimistic) assumption that at least 1/8 person-day would be required for a manual recording per process, the total effort without AI support would be around 450 person-days.
In contrast, AI-supported data capture requires quality assurance of the generated results, since – at least currently – no LLM delivers error-free results. If we assume that 80% of the generated content requires a brief revision, then, based on an estimated 15 minutes per process, including the initial generation time for SGB V, this results in a workload of approximately 90 person-days. This is an assumption with a high safety margin, which was completed significantly faster in the examples shown.
If we compare both approaches, the AI-supported creation of a Business Architecture results in a productivity gain of around 80%.
Is it possible to better tailor the architecture model to one’s own organization by using individual content, instead of just receiving „AI-generated platitudes“?
By integrating your own content (e.g. unstructured internal documents), it is possible to quickly and specifically adapt the results of AI generation to your own circumstances. Compared to manual modeling, this produces the efficiency advantage discussed above. More importantly, however, is that the content of your own organization is used, rather than an external LLM delivering general results that do not reflect your individual situation. The hybrid approach presented enables a data protection-friendly way, so that even confidential internal documents can be included in the model creation. Cloud providers cannot achieve this.
Can strategic, organizational, and technical decisions be simplified and accelerated using a model created in this way?
By providing comprehensive analyses based on the Knowledge Graph, it is possible to answer strategic, organizational, and technical questions quickly and with minimal effort. For example, a generated information flow diagram provides an overview of organizational and information technology interfaces, with reference to use cases and processes by the push of a button. Of course, the quality of the analyses depends on the quality of the underlying Knowledge Graph. If this quality is high, it will provide an ideal basis for preparing and supporting decisions at management levels.
Are we facing a fundamental change in the way Business Architectures are created and “operated”?
Yes. It will take some time before these approaches become widespread, but they cannot be stopped. The path to this will involve intermediate stages in which automated (generative) and manual architecture management techniques will coexist. My prediction is that we will soon see „architecture assistants“ assisting human architects. Architects should prepare for the new world today. The need to build AI knowledge is also important for them.
Is the time of classic modeling tools over?
Here, too, a resounding yes, even if the end isn’t in sight tomorrow. Manual work in creating Business Architectures will still be necessary for some time, as we saw in the example of the generated BPMN diagram. For the time being, this will still require specialized modeling tools. However, progress in the automatic generation of Business Architectures, including the generation of business diagrams, clearly shows that their days are numbered. Architects must find an answer to the question: “Are you already generating or are you still modeling?”
Sources:
[1]: Exploring AI- driven approaches for unstructured document analysis and future horizons
[2]: AI Agents : Evolution, Architecture, and Real-World Applications
[3]: Generative AI architecture for enterprises : Development frameworks , tools , implementation , and future trends
[4]: Machine learning operations
[5]: Applying Large Language Models in Knowledge Graph- based Enterprise Modeling: Challenges and Opportunities
[6]: Design of a Tool for Requirements Extraction from Legal Documents
[7]: An overview of information extraction techniques for legal documents analysis and processing